Document AI Fields
Umango can use artificial intelligence (AI) to analyze documents and automatically capture data based on a document type.
To use AI, each job is assigned a document type. When uploading the first sample document in a job the user is prompted to decide if AI will be enabled and if so, what engine and document type should be set.
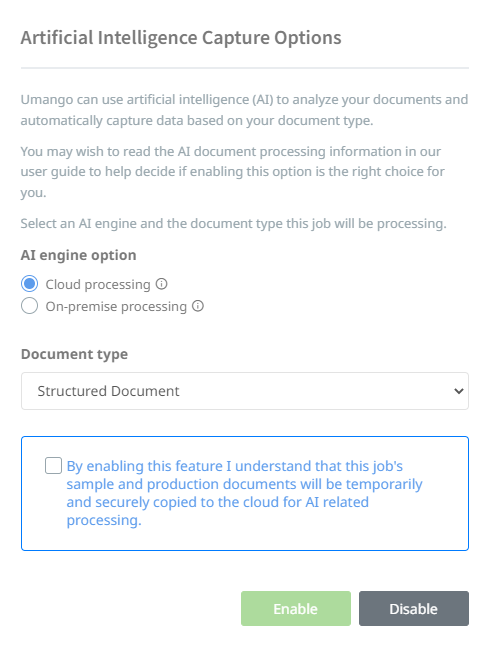
Enabling Document AI in a Job
You can choose to enable AI when prompted or enable it at any time in the life cycle of a job. AI can be disabled or enabled using the Enable AI and DIsable AI buttons located within the zones tab.
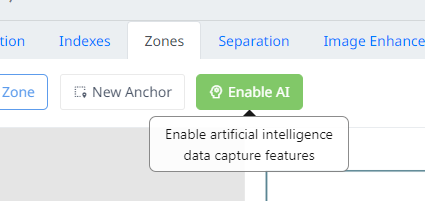
Enabling Document AI
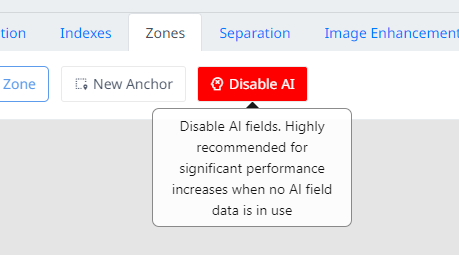
Disabling Document AI
You may find that AI is not required or that other methods of data capture are more suited to your requirements. You may also find that your documents are not suited to capturing with AI.
Note: It is strongly recommended that AI be disabled unless you require it in your job. AI processing adds a significant time overhead to your document processing.
Read on to determine AI's suitability for your use case.
Selecting An AI Engine
There are a number of points for consideration when choosing the correct AI engine for processing documents. These include:
|
Consideration |
Cloud Processing |
On-Premise Processing |
|
Internet connection |
Required |
Not required |
|
Security |
Documents are temporarily and securely copied to the cloud during processing |
Documents do not leave the Umango server during processing |
|
Language support |
Limited (see supported language table below) |
All OCR languages* |
|
Accuracy |
Highly accurate |
Less accurate |
|
Document type |
Supports common semi-structured document types and structured documents |
Only supports documents that have a consistent structure |
|
Flexibility of document structure (data can be anywhere in the document) |
Highly flexible for semi-structured document types (eg. invoice and receipt document types) |
Only structured documents are supported |
|
Line item extraction |
Invoice line items are extracted |
Not supported |
|
Table extraction |
Table cells are detected and extracted and table rows. Column names are also detected. |
Table cells are detected and extracted and table rows |
|
Handwriting recognition |
Supported |
Not supported |
|
Speed of processing |
Slower (also dependent on internet connection speed) |
Faster (not dependent on an internet connection) |
Selecting A Document Type
For the purpose of AI capture, document types fall into 3 basic categories:
- Semi-structured documents: The data expected on the documents is reasonably consistent but its location may not be. Examples include invoices, business cards, receipts etc.
- Structured Documents: The appearance of the document and the data it contains is consistent. Data will be located in the same location on every document processed
- Unstructured Documents: The data on the documents will be located anywhere within the document and the type of document does not fall into one of the available semi-structured document types. These documents are not suitable for AI data capture in Umango.
AI Data Field Categories
Within the semi-structured document category, the Umango cloud AI engine supports various common document types. During processing the AI engine will search for data common to each document type. These data fields are known as "standard fields" in Umango and in most instances are preferred. In addition, the AI engine may find data that it thinks is useful and these additional data values are called "structured document fields". These structured document fields may not appear on every document unless the documents being processed are of the same structure (layout).
For example, when processing invoices, Umango will try to find an invoice number, invoice date, part numbers, item quantities and an invoice total etc. These are among the data fields expected on every invoice and will consistently be captured if present anywhere on the document. These are "standard data fields". In addition, peripheral data fields may be found. These "structured fields" are useful when all the documents to be processed in a job will be the same structure. For example, if all the invoices to be processed in a job will to be coming from the same supplier then the structured fields would be consistently captured and usable.
All data captured using the structured document type option will be captured as "structured document fields".
Languages Supported
Some document types will be more accurate than others when certain languages are contained on the documents. For on-premise AI processing, all Umango's OCR languages are supported. However, for cloud processing, it is dependent on the document type in use.
Note About Taxes
In the Invoice document type, the TaxDetails field collection is only trained for collecting tax type information for India, Germany, Spain, Portugal and Canada. In other regions, tax information is provided as a total in the TotalTax field or in some instances on the line item level in the Item.Tax field.
The AI engines are tuned for the languages/regions below:
|
Document Type |
Cloud Processing |
On-Premise Processing |
|
Handwritten Text |
Arabic, Chinese Simplified, English, French, German, Italian, Japanese, Korean, Portuguese, Russian, Spanish, Thai |
Not supported |
|
Invoices/Purchase Orders |
Albanian, Arabic, Bulgarian, Chinese (simplified), Chinese (traditional), Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hebrew, Hungarian, Icelandic, Italian, Japanese, Korean, Latvian, Lithuanian, Macedonian, Malay, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian (Cyrillic), Serbian (Latin), Slovak, Slovenian, Spanish, Swedish, Thai, Turkish, Ukrainian, Vietnamese |
Not supported |
|
Receipts |
Afrikaans, Akan, Albanian, Arabic, Azerbaijani, Bamanankan, Basque, Belarusian, Bhojpuri, Bosnian, Bulgarian, Catalan, Cebuano, Corsican, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Fijian, Filipino, Finnish, French, Galician, Ganda, German, Greek, Guarani, Haitian Creole, Hawaiian, Hebrew, Hindi, Hmong Daw, Hungarian, Icelandic, Igbo, Iloko, Indonesian, Irish, isiXhosa, isiZulu, Italian, Japanese, Javanese, Kazakh, Kazakh (Latin), Kinyarwanda, Kiswahili, Korean, Kurdish, Kurdish (Latin), Kyrgyz, Latin, Latvian, Lingala, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Maltese, Maori, Marathi, Maya, Yucatán, Mongolian, Nepali, Norwegian, Nyanja, Oromo, Pashto, Persian, Persian (Dari), Polish, Portuguese, Punjabi, Quechua, Romanian, Russian, Samoan, Sanskrit, Scottish Gaelic, Serbian (Cyrillic), Serbian (Latin), Sesotho, Sesotho sa Leboa, Shona, Slovak, Slovenian, Somali (Latin), Spanish, Sundanese, Swedish, Tahitian, Tajik, Tamil, Tatar, Tatar (Latin), Thai, Tongan, Turkish, Turkmen, Ukrainian, Upper Sorbian, Uyghur, Uyghur (Arabic), Uzbek, Uzbek (Latin), Vietnamese, Welsh, Western Frisian, Xitsonga |
Not supported |
|
Business Cards |
English, Japanese |
Not supported |
|
ID Cards |
Worldwide: Passport Book, Passport Card United States: Driver License, Identification Card, Residency Permit (Green card), Social Security Card, Military ID Europe: Driver License, Identification Card, Residency Permit India: Driver License, PAN Card, Aadhaar Card Canada: Driver License, Identification Card, Residency Permit Australia: Driver License, Photo Card, Key-pass ID |
Not supported |
|
Contract/Agreement |
English |
Not supported |
|
Structured Documents (Machine Print) |
Abaza, Abkhazian, Achinese, Acoli, Adangme, Adyghe, Afar, Afrikaans, Akan, Albanian, Algonquin, Angika (Devanagari), Arabic, Asturian, Asu (Tanzania), Avaric, Awadhi-Hindi (Devanagari), Aymara, Azerbaijani (Latin), Bafia, Bagheli, Bambara, Bashkir, Basque, Belarusian (Cyrillic), Belarusian (Latin), Bemba (Zambia), Bena (Tanzania), Bhojpuri-Hindi (Devanagari), Bikol, Bini, Bislama, Bodo (Devanagari), Bosnian (Latin), Brajbha, Breton, Bulgarian, Bundeli, Buryat (Cyrillic), Catalan, Cebuano, Chamling, Chamorro, Chechen, Chhattisgarhi (Devanagari), Chiga, Chinese Simplified, Chinese Traditional, Choctaw, Chukot, Chuvash, Cornish, Corsican, Cree, Creek, Crimean Tatar (Latin), Croatian, Crow, Czech, Danish, Dargwa, Dari, Dhimal (Devanagari), Dogri (Devanagari), Duala, Dungan, Dutch, Efik, English, Erzya (Cyrillic), Estonian, Faroese, Fijian, Filipino, Finnish, Fon, French, Friulian, Ga, Gagauz (Latin), Galician, Ganda, Gayo, German, Gilbertese, Gondi (Devanagari), Greek, Greenlandic, Guarani, Gurung (Devanagari), Gusii, Haitian Creole, Halbi (Devanagari), Hani, Haryanvi, Hawaiian, Hebrew, Herero, Hiligaynon, Hindi, Hmong Daw (Latin), Ho(Devanagiri), Hungarian, Iban, Icelandic, Igbo, Iloko, Inari Sami, Indonesian, Ingush, Interlingua, Inuktitut (Latin), Irish, Italian, Japanese, Jaunsari (Devanagari), Javanese, Jola-Fonyi, Kabardian, Kabuverdianu, Kachin (Latin), Kalenjin, Kalmyk, Kangri (Devanagari), Kanuri, Karachay-Balkar, Kara-Kalpak (Cyrillic), Kara-Kalpak (Latin), Kashubian, Kazakh (Cyrillic), Kazakh (Latin), Khakas, Khaling, Khasi, K'iche', Kikuyu, Kildin Sami, Kinyarwanda, Komi, Kongo, Korean, Korku, Koryak, Kosraean, Kpelle, Kuanyama, Kumyk (Cyrillic), Kurdish (Arabic), Kurdish (Latin), Kurukh (Devanagari), Kyrgyz (Cyrillic), Lak, Lakota, Latin, Latvian, Lezghian, Lingala, Lithuanian, Lower Sorbian, Lozi, Lule Sami, Luo (Kenya and Tanzania), Luxembourgish, Luyia, Macedonian, Machame, Madurese, Mahasu Pahari (Devanagari), Makhuwa-Meetto, Makonde, Malagasy, Malay (Latin), Maltese, Malto (Devanagari), Mandinka, Manx, Maori, Mapudungun, Marathi, Mari (Russia), Masai, Mende (Sierra Leone), Meru, Meta', Minangkabau, Mohawk, Mongolian (Cyrillic), Mongondow, Montenegrin (Cyrillic), Montenegrin (Latin), Morisyen, Mundang, Nahuatl, Navajo, Ndonga, Neapolitan, Nepali, Ngomba, Niuean, Nogay, North Ndebele, Northern Sami (Latin), Norwegian, Nyanja, Nyankole, Nzima, Occitan, Ojibwa, Oromo, Ossetic, Pampanga, Pangasinan, Papiamento, Pashto, Pedi, Persian, Polish, Portuguese, Punjabi (Arabic), Quechua, Ripuarian, Romanian, Romansh, Rundi, Russian, Rwa, Sadri (Devanagari), Sakha, Samburu, Samoan (Latin), Sango, Sangu (Gabon), Sanskrit (Devanagari), Santali(Devanagiri), Scots, Scottish Gaelic, Sena, Serbian (Cyrillic), Serbian (Latin), Shambala, Shona, Siksika, Sirmauri (Devanagari), Skolt Sami, Slovak, Slovenian, Soga, Somali (Arabic), Somali (Latin), Songhai, South Ndebele, Southern Altai, Southern Sami, Southern Sotho, Spanish, Sundanese, Swahili (Latin), Swati, Swedish, Tabassaran, Tachelhit, Tahitian, Taita, Tajik (Cyrillic), Tamil, Tatar (Cyrillic), Tatar (Latin), Teso, Tetum, Thai, Thangmi, Tok Pisin, Tongan, Tsonga, Tswana, Turkish, Turkmen (Latin), Tuvan, Udmurt, Uighur (Cyrillic), Ukrainian, Upper Sorbian, Urdu, Uyghur (Arabic), Uzbek (Arabic), Uzbek (Cyrillic), Uzbek (Latin), Vietnamese, Volapük, Vunjo, Walser, Welsh, Western Frisian, Wolof, Xhosa, Yucatec Maya, Zapotec, Zarma, Zhuang, Zulu |
All OCR languages* |
* Some languages are only supported when the extended language support option is enabled in the Umango license
This doesn’t mean Umango can’t read documents containing languages not included in the ones mentioned above (as long as they are based on the English character set) but accuracy may be diminished.
For details on configuring Umango to validate AI field data within a zone, read the zone properties section.