OCR Text Zones
Example use cases:
|
When a zone is set to OCR text, Umango automatically captures machine printed text within the region during processing. Alternatively, the operator can manually select a region and OCR the text using the lasso tool.
The OCR zone type can be set to capture all the content within the zone, or by configuring the Smart Seek options, search for words or characters within the region and extract and/or highlight a value near it. For more information, see the section on Smart Seek
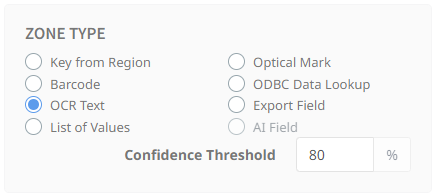
Note: Umango is designed to capture machine print, not handwriting. If you must capture handwriting, we would recommend selecting the Tesseract OCR engine or use a key from region zone and have the user manually enter the data.
OCR Options
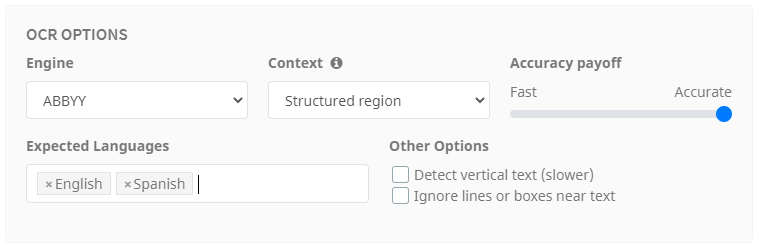
Engine
Umango offers four OCR engine options, ABBYY, Tesseract, Cloud or "Use Best Result". All engines have their strengths and weaknesses when presented with different scenarios. It is best to try each engine and select the most appropriate based on the zone's unique requirements and how it analyzes the text. If unsure, Umango can make this selection for you each time you process a zone (note that selecting this option will significantly increase processing time).
Context
OCR context affects how the region is analyzed and offers three different configurations.
- Block of text: An area with multiple lines of text. A typical example might be an address block. If unsure which context to select, use this option.
- Structured region: A larger area on the document that contains lines, boxes, images, text, etc. In this situation, there is more to be analyzed than just text. This might typically be used for a Smart Seek with a large capture.
- Line of text: A constrain zone where everything is being read inside and there is only one expected line of text. With this option, and when smart seek is not in use, white characters and format regex assist with capture accuracy.
By using a context type and telling Umango what to expect, the accuracy and reliability of the read increases. It may be useful to test the zone with each of the context types to see what works best for your scenario and documents.
Accuracy Payoff
Adjust the slider depending on a preference for speed (faster capture and processing speed, less accurate read) or accuracy (more accurate read, slower capture and processing).
Expected Languages
Enter the languages expected in the OCR region. There can be as many languages as needed, although the fewer languages constrained, the greater the accuracy and speed of the capture. If there are more than one, separate each by a comma or press tab.
Detect Vertical Text
Umango offers the option to detect and read vertical text in the zone. Be aware that enabling this can result in a slower capture, so selecting this option when not necessary is not recommended.
Ignore Lines
The option to Ignore lines or boxes near text can be used when text is being read within a box or lines are obscuring it. Umango can attempt to ignore those lines in order to read the text with greater accuracy. The lines are not permanently removed from the document and the resulting document will not be affected.